Good site for advice on cooling your pc while keep noise levels to near silent J
http://www.silentpcreview.com/
Wednesday, 25 February 2009
Tuesday, 17 February 2009
SQL replace cursor with while loop
The key here is to get all the item categories which fit our WHERE clause into a memory table and use the Primary Key of this table to pick up each successive item category.
1: --Declare variables
2: DECLARE @item_category_id INT
3: DECLARE @order_id INT
4: DECLARE @purchase_order_id INT
5: 6: --Declare a memory table
7: DECLARE @item_table TABLE (primary_key INT IDENTITY(1,1) NOT NULL, --THE IDENTITY STATEMENT IS IMPORTANT!
8: item_category_id INT,
9: order_id INT
10: ) 11: 12: --now populate this table with the required item category values
13: INSERT INTO @item_table
14: SELECT -- Same SELECT statement as that for the CURSOR
15: it.item_category_id 16: ,ord.order_id17: FROM dbo.item_categories it
18: 19: INNER JOIN dbo.orders ord
20: ON ord.item_category_id = it.item_category_id
21: 22: WHERE ord.order_date >= '1-sep-05'
23: and it.isSuspended != 1
24: 25: DECLARE @item_category_counter INT
26: DECLARE @loop_counter INT
27: 28: SET @loop_counter = ISNULL(SELECT COUNT(*) FROM @item_table),0) -- Set the @loop_counter to the total number of rows in the
29: -- memory table
30: 31: SET @item_category_counter = 1
32: 33: WHILE @loop_counter > 0 AND @item_category_counter <= @loop_counter
34: BEGIN
35: SELECT @item_category_id = item_category_id
36: ,@order_id = order_id37: FROM @item_table
38: WHERE primary_key = @item_category_counter
39: 40: --Now pass the item-category_id and order_id to the OUTPUT stored procedure
41: EXEC dbo.usp_generate_purchase_order @item_category_id, @order_id, @purchase_order_id OUTPUT
42: 43: /*44: Call other code here to process your pruchase order for this item
45: */ 46: 47: SET @item_category_counter = @item_category_counter + 1
48: ENDFriday, 13 February 2009
SQL Statistics information
from an amazing blog post here http://www.mssqltips.com/tip.asp?tip=1550 : (recommended to read)
ALTER PROCEDURE [dbo].[usp_Detail_Index_Stats] @table_name sysname
AS
----------------------------------------------------------------------------------
-- ******VARIABLE DECLARATIONS******
----------------------------------------------------------------------------------
DECLARE @IndexTable TABLE
(
[Database] sysname, [Table] sysname, [Index Name] sysname NULL, index_id smallint,
[object_id] INT, [Index Type] VARCHAR(20), [Alloc Unit Type] VARCHAR(20),
[Avg Frag %] decimal(5,2), [Row Ct] bigint, [Stats Update Dt] datetime
)
DECLARE @dbid smallint --Database id for current database
DECLARE @objectid INT --Object id for table being analyzed
DECLARE @indexid INT --Index id for the target index for the STATS_DATE() function
----------------------------------------------------------------------------------
-- ******VARIABLE ASSIGNMENTS******
----------------------------------------------------------------------------------
SELECT @dbid = DB_ID(DB_NAME())
SELECT @objectid = OBJECT_ID(@table_name)
----------------------------------------------------------------------------------
-- ******Load @IndexTable with Index Metadata******
----------------------------------------------------------------------------------
INSERT INTO @IndexTable
(
[Database], [Table], [Index Name], index_id, [object_id],
[Index Type], [Alloc Unit Type], [Avg Frag %], [Row Ct]
)
SELECT
DB_NAME() AS "Database"
@table_name AS "Table"
SI.NAME AS "Index Name"
IPS.index_id, IPS.OBJECT_ID, --These fields included for joins only
IPS.index_type_desc, --Heap, Non-clustered, or Clustered
IPS.alloc_unit_type_desc, --In-row data or BLOB data
CAST(IPS.avg_fragmentation_in_percent AS decimal(5,2)),
IPS.record_count
FROM sys.dm_db_index_physical_stats (@dbid, @objectid, NULL, NULL, 'sampled') IPS
LEFT JOIN sys.sysindexes SI ON IPS.OBJECT_ID = SI.id AND IPS.index_id = SI.indid
WHERE IPS.index_id <> 0
----------------------------------------------------------------------------------
-- ******ADD STATISTICS INFORMATION******
----------------------------------------------------------------------------------
DECLARE curIndex_ID CURSOR FOR
SELECT I.index_id
FROM @IndexTable I
ORDER BY I.index_id
OPEN curIndex_ID
FETCH NEXT FROM curIndex_ID INTO @indexid
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @IndexTable
SET [Stats Update Dt] = STATS_DATE(@objectid, @indexid)
WHERE [object_id] = @objectid AND [index_id] = @indexid
FETCH NEXT FROM curIndex_ID INTO @indexid
END
CLOSE curIndex_ID
DEALLOCATE curIndex_ID
----------------------------------------------------------------------------------
-- ******RETURN RESULTS******
----------------------------------------------------------------------------------
SELECT I.[Database], I.[Table], I.[Index Name], "Index Type"=
CASE I.[Index Type]
WHEN 'NONCLUSTERED INDEX' THEN 'NCLUST'
WHEN 'CLUSTERED INDEX' THEN 'CLUST'
ELSE 'HEAP'
END,
I.[Avg Frag %], I.[Row Ct],
CONVERT(VARCHAR, I.[Stats Update Dt], 110) AS "Stats Dt"
FROM @IndexTable I
ORDER BY I.[Index Type], I.[index_id]
More on SQL indexes
the command to show index statistics:
dbcc show_statistics (tablename, indexname)
The lower the "All density" value the better, means the index is highly selective.
--
How to view index fragmentation (replace database and table names)
How to reorganise an index (online operation) - only affects the leaf nodes.
To rebuild the index without taking the database offline you need the enterprise edition of MSSQL 2005.
If space is an issue it is better to disable a nonclustered index before rebuilding it, then we only need about 20% of the index size as free space to do the rebuild.
Also the Fill Factor can be adjusted based on how we expect the data to be used. This specifies how full the data pages or leaf level index pages will be. Lower fill factor is better when there are many data updates and inserts.
dbcc show_statistics (tablename, indexname)
The lower the "All density" value the better, means the index is highly selective.
--
How to view index fragmentation (replace database and table names)
1: select str(s.index_id,3,0) as indid,
2: left(i.name, 20) as index_name,
3: left(index_type_desc, 20) as index_type_desc,
4: index_depth as idx_depth,
5: index_level as level,
6: str(avg_fragmentation_in_percent, 5,2) as avg_frgmnt_pct,
7: str(page_count, 10,0) as pg_cnt
8: FROM sys.dm_db_index_physical_stats
9: (db_id('_DBNAME_<dbname>'), object_id('<tablename>_TABLENAME_'),1, 0, 'DETAILED') s
10: join sys.indexes i on s.object_id = i.object_id and s.index_id = i.index_id
How to reorganise an index (online operation) - only affects the leaf nodes.
1: 2: ALTER INDEX <indexname> _INDEXNAME_ on _TABLENAME_ <tablename> REORGANIZE
1: ALTER INDEX _INDEXNAME_ on _TABLENAME_ REBUILD
If space is an issue it is better to disable a nonclustered index before rebuilding it, then we only need about 20% of the index size as free space to do the rebuild.
Also the Fill Factor can be adjusted based on how we expect the data to be used. This specifies how full the data pages or leaf level index pages will be. Lower fill factor is better when there are many data updates and inserts.
Thursday, 12 February 2009
Clustered and non-clustered indexes in MSSQL server
Columns to include in clustered index
. Those that are often accessed sequentially
. Those that contain a large number of distinct values
. Those that are used in range queries that use operators such as BETWEEN, >
<= in the WHERE clause . Those that are frequently used by queries to join or group the result set When to use non-clustered index . Queries that do not return large result sets . Columns that are frequently used in the WHERE clause that return exact match . Columns that have many distinct values (that is, high cardinality) . All columns referenced in a critical query (A special nonclustered index called a covering index that eliminates the need to go to the underlying data pages.) (based on the book SQL Server 2005 Unleashed, Sams 2006). Note: if there are columns usually required in the results but not in the query conditions, we can add them as "included columns" (for non-clustered index), which means they will exist in the leaf nodes of the index for faster retrieval. This is similar to a covering index (same?) To improve index performance, we can "REBUILD" them (drop and recreate) or just "REORGANIZE" them (like defrag, without drop). When we reorganise we have the option to compact large objects. Index can be disabled, in this case if we rebuild it we don't need to have extra temp space. Index can be applied on a view, but there are several conditions that must be met before this can be done. See online documentation. A composite index will only be used optimally (i.e. index seek instead of index scan) if its first column is part of the search argument or join clause. When deciding on an index another parameter to consider is the selectivity of the index i.e. the number of distinct rows returned on the index keys / number of rows in the table. The higher this number the better. e.g.
as a rule of thumb we require this to be > 0.85
Example sql code to determine the statistical distribution of values for a specific column
. Those that are often accessed sequentially
. Those that contain a large number of distinct values
. Those that are used in range queries that use operators such as BETWEEN, >
<= in the WHERE clause . Those that are frequently used by queries to join or group the result set When to use non-clustered index . Queries that do not return large result sets . Columns that are frequently used in the WHERE clause that return exact match . Columns that have many distinct values (that is, high cardinality) . All columns referenced in a critical query (A special nonclustered index called a covering index that eliminates the need to go to the underlying data pages.) (based on the book SQL Server 2005 Unleashed, Sams 2006). Note: if there are columns usually required in the results but not in the query conditions, we can add them as "included columns" (for non-clustered index), which means they will exist in the leaf nodes of the index for faster retrieval. This is similar to a covering index (same?) To improve index performance, we can "REBUILD" them (drop and recreate) or just "REORGANIZE" them (like defrag, without drop). When we reorganise we have the option to compact large objects. Index can be disabled, in this case if we rebuild it we don't need to have extra temp space. Index can be applied on a view, but there are several conditions that must be met before this can be done. See online documentation. A composite index will only be used optimally (i.e. index seek instead of index scan) if its first column is part of the search argument or join clause. When deciding on an index another parameter to consider is the selectivity of the index i.e. the number of distinct rows returned on the index keys / number of rows in the table. The higher this number the better. e.g.
1: select count(distinct surname) from sometable / select count(*) from sometable
as a rule of thumb we require this to be > 0.85
Example sql code to determine the statistical distribution of values for a specific column
1: select state, count(*) as numrows, count(*)/b.totalrows * 100 as percentage
2: from authors a, (select convert(numeric(6,2), count(*)) as totalrows from authors) as b group by state, b.totalrows
3: having count(*) > 1
4: order by 2 desc
5: goFriday, 6 February 2009
SQL datetime as string representation
1: CONVERT(VARCHAR(10), [StartDate], 103)
Also experiment with different values instead of 10, to get only the days/month part of date for example.
Thursday, 5 February 2009
GreyBox popup window with C# ASP.NET DataBound GridView application
GreyBox is a nice free animated popup window: http://orangoo.com/labs/GreyBox/
In order to get it to work dynamically with a databound GridView in ASP.NET in C# I had to make the following change in the .aspx page:
in the part of the gridview definition, added another template field:
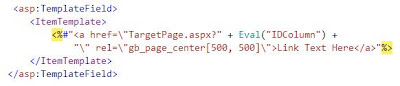
and of course include the greybox folder in the website, and the correct entries in the header section. I hope this helps someone, it took me some time to figure out.
In order to get it to work dynamically with a databound GridView in ASP.NET in C# I had to make the following change in the .aspx page:
in the

Subscribe to:
Comments (Atom)