First, worth to try the VS built in converter.
Another one that looks good, worth a try http://www.aivosto.com/project/vbnet.html - says it works with previous versions and there is trial for small projects.
Microsoft Visual Basic 6.0 Code Advisor can be used on VB6 before converting to VB.NET:
http://msdn.microsoft.com/en-us/vbasic/ms789135.aspx
Finally a couple of more:
http://www.vbto.net/
http://www.vbmigration.com/editions.aspx
Other useful links for migration of VB6 to .NET
http://blogs.msdn.com/ericnel/archive/2008/04/25/visual-basic-6-migration-to-net.aspx
http://msdn.microsoft.com/en-gb/vbrun/ms788233.aspx
http://msdn.microsoft.com/en-gb/dd408373.aspx
Finally here is a promissing link for 5 to 6 but can't follow it at the moment: http://www.topblogarea.com/sitedetails_17682-2.html
Monday, 28 September 2009
Thursday, 24 September 2009
how to get the default schema for a user in MSSQL 2005
execute the stored procedure sp_helpuser, for example
sp_helpuser 'domainname\username'
One of the resulting columns is DefSchemaName.
There is a similar proc sp_helpgroup to show the users in a group but does not include schema information.
Another way to get the schema information is
select name, default_schema_namefrom sys.database_principals uwhere u.name='username'
sp_helpuser 'domainname\username'
One of the resulting columns is DefSchemaName.
There is a similar proc sp_helpgroup to show the users in a group but does not include schema information.
Another way to get the schema information is
select name, default_schema_namefrom sys.database_principals uwhere u.name='username'
Wednesday, 23 September 2009
Tuesday, 22 September 2009
SQL tutorials
Nice website with tutorial but requires google gears to run the examples.
http://www.bin-co.com/database/sql_tutorial/
Visual Explanation of JOINs http://www.codinghorror.com/blog/archives/000976.html
http://www.bin-co.com/database/sql_tutorial/
Visual Explanation of JOINs http://www.codinghorror.com/blog/archives/000976.html
SQL replicate permissions (copy)
Found the following cool script at http://vyaskn.tripod.com/scripting_permissions_in_sql_server_2005.htm
along with a very good explanation
along with a very good explanation
1: SET NOCOUNT ON
2: DECLARE @OldUser sysname, @NewUser sysnameSET @OldUser = 'HRUser'SET @NewUser = 'PersonnelAdmin'
3: SELECT 'USE' + SPACE(1) + QUOTENAME(DB_NAME()) AS '--Database Context'SELECT '--Cloning permissions from' + SPACE(1) + QUOTENAME(@OldUser) + SPACE(1) + 'to' + SPACE(1) + QUOTENAME(@NewUser) AS '--Comment'SELECT 'EXEC sp_addrolemember @rolename =' + SPACE(1) + QUOTENAME(USER_NAME(rm.role_principal_id), '''') + ', @membername =' + SPACE(1) + QUOTENAME(@NewUser, '''') AS '--Role Memberships'
4: FROM sys.database_role_members AS rm
5: WHERE USER_NAME(rm.member_principal_id) = @OldUser
6: ORDER BY rm.role_principal_id ASC
7: SELECT CASE
8: WHEN perm.state <> 'W'
9: THEN perm.state_desc
10: ELSE 'GRANT'
11: END + SPACE(1) + perm.permission_name + SPACE(1) + 'ON ' + QUOTENAME(USER_NAME(obj.schema_id)) + '.' + QUOTENAME(obj.name) +
12: CASE WHEN cl.column_id IS NULL THEN SPACE(0)
13: ELSE '(' + QUOTENAME(cl.name) + ')'
14: END + SPACE(1) + 'TO' + SPACE(1) + QUOTENAME(@NewUser)
15: COLLATE database_default + CASE WHEN perm.state <> 'W'
16: THEN SPACE(0)
17: ELSE SPACE(1) + 'WITH GRANT OPTION' END AS '--Object Level Permissions'
18: FROM sys.database_permissions AS perm
19: INNER JOIN sys.objects AS obj ON perm.major_id = obj.[object_id]
20: INNER JOIN sys.database_principals AS usr
21: ON perm.grantee_principal_id = usr.principal_id
22: LEFT JOIN sys.columns AS cl
23: ON cl.column_id = perm.minor_id
24: AND cl.[object_id] = perm.major_id
25: WHERE usr.name = @OldUser
26: ORDER BY perm.permission_name ASC, perm.state_desc ASC
27: SELECT CASE WHEN perm.state <> 'W' THEN perm.state_desc
28: ELSE 'GRANT' END + SPACE(1) + perm.permission_name + SPACE(1) + SPACE(1) + 'TO' + SPACE(1) + QUOTENAME(@NewUser)
29: COLLATE database_default +
30: CASE WHEN perm.state <> 'W' THEN SPACE(0) ELSE SPACE(1) + 'WITH GRANT OPTION' END AS '--Database Level Permissions'
31: FROM sys.database_permissions AS perm
32: INNER JOIN sys.database_principals AS usr
33: ON perm.grantee_principal_id = usr.principal_id
34: WHERE usr.name = @OldUser
35: AND perm.major_id = 0
36: ORDER BY perm.permission_name ASC, perm.state_desc ASC
Saturday, 19 September 2009
outlook express with windows live email and o2 smtp settings
Finally I got this to work, the tricky bit was using SMTP port not the 25 default but 587 (as I discovered somewhere on the web). Here are the screenshots of the settings:
The server settings:

The server settings:
 The server authentication settings:
The server authentication settings:

Note that in the above image you can enable the "Log on using Secure Password Authentication" and it will still work. Or you can use the option "Use same settings as my incoming mail server" and it will still work - actually this is a bit easier since you dont have to enter the same information twice.
Finally the advanced settings:
Wednesday, 9 September 2009
XML and XPATH editor : SketchPath
Free and open source not open source: http://pgfearo.googlepages.com/
Update Nov 2012:
On the original page now states:
SketchPath as a product has evolved into 2 very different products that include SketchPath's powerful XPath features, but also bring new features to the mix:
Update Nov 2012:
On the original page now states:
SketchPath as a product has evolved into 2 very different products that include SketchPath's powerful XPath features, but also bring new features to the mix:
XMLQuire
Windows XML editor with integrated XPath 1.0 editor
Pathenq
Simple, yet powerful web-based XPath 2.0 editor - with built-in diagnostics tools
The first one is free, the second online. A very good tool.
Tuesday, 8 September 2009
Monday, 7 September 2009
ForFiles command - windows server 2008
forfiles command is quite useful as it has the /d switch (date) which can be set to less than 30 days (-30) or more. The /m is a mask that you can set to the extension of files you wish to find to save you from doing a *.*. Then it will do the command in “ “ for each file that meets the criteria.
Example
This deletes any files in c:\a:\test and its subdirectories that are older than 30 days:
Example
This deletes any files in c:\a:\test and its subdirectories that are older than 30 days:
1: forfiles /p /m *.txt c:\a\test /s /c "cmd /c del @file" /d -30
Thursday, 13 August 2009
TightVNC and UltraVNC
seems like ultra vnc http://uvnc.com/ is being more actively developed and has more features than tightvnc, but tightvnc has released a new version after a long time http://www.tightvnc.com/
Friday, 31 July 2009
read and write data
1: using System;
2: using System.Collections.Generic;
3: using System.IO;
4: using System.Text;
5: using System.Windows.Forms;
6: namespace ReadData
7: {8: public partial class Form1 : Form
9: {10: static readonly StringBuilder outData = new StringBuilder();
11: readonly List<double> a = new List<double>(); // the 2 input TSs
12: readonly List<double> b = new List<double>();
13: public Form1()
14: { 15: InitializeComponent(); 16: }17: void Form1_Load(object sender, EventArgs e)
18: { 19: LoadData();20: int totalFound = 0;
21: double lastDiff = 0;
22: bool haveEntry = false;
23: const int window = 100; // how many values we use to estimate mean and stdDev
24: for (int i = window; i <= a.Count; i++)
25: //for (int i = 144; i < 145; i++) // one sample only, for testing
26: {27: double meanA = GetMean(a, i - window, i);
28: double meanB = GetMean(b, i - window, i);
29: double stdA = GetStd(a, i - window, i, meanA);
30: double stdB = GetStd(b, i - window, i, meanB);
31: double aNorm = (a[i - 1] - meanA) / stdA;
32: double bNorm = (b[i - 1] - meanB) / stdB;
33: double diff = aNorm - bNorm;
34: double absDiff = Math.Abs(diff);
35: if (haveEntry && ((lastDiff > 1 && diff <> -1)))
36: {37: Console.WriteLine("==== Exit index " + i);
38: haveEntry = false;
39: }40: //outData.AppendLine(i + ", " + diff); // for writing to file
41: // outData.AppendLine(diff.ToString()); // for writing to file
42: outData.AppendLine(string.Format("{0:d4}", i-window+1) + " " + diff); // for writing to file
43: if (absDiff > 15)
44: { 45: totalFound++;46: Console.WriteLine("Found at index " + i + " diff " + diff);
47: if (absDiff < Math.Abs(lastDiff) && !haveEntry)
48: {49: Console.WriteLine("==== Entry index " + i);
50: haveEntry = true;
51: } 52: } 53: lastDiff = diff; 54: }55: Console.WriteLine("total found " + totalFound);
56: WriteData(); 57: }58: static void WriteData()
59: {60: const string fileout = "out.csv";
61: if (File.Exists(fileout))
62: { 63: File.Delete(fileout); 64: }65: using (StreamWriter sw = new StreamWriter(fileout))
66: { 67: sw.Write(outData.ToString()); 68: } 69: }70: static double GetStd(IList<double> array, int start, int limit, double mean)
71: {72: double sum = 0;
73: for (int i = start; i < limit; i++)
74: { 75: sum += (array[i] - mean) * (array[i] - mean); 76: } 77: sum = Math.Sqrt(sum); 78: sum /= (limit - start);79: return sum;
80: }81: static double GetMean(IList<double> array, int start, int limit)
82: {83: double sum = 0;
84: for (int i = start; i < limit; i++)
85: { 86: sum += array[i]; 87: } 88: sum /= (limit - start);89: return sum;
90: }91: /// <summary>
92: /// Assume input file has 2 columns, one for each TS we want to track.
93: /// </summary>
94: void LoadData()
95: {96: using (StreamReader sr = new StreamReader("5m-db.csv"))
97: {98: string newData;
99: a.Clear(); 100: b.Clear();101: while (sr.Peek() != -1)
102: { 103: newData = sr.ReadLine();104: string[] line = newData.Split(',');
105: a.Add(double.Parse(line[0]));
106: b.Add(double.Parse(line[1]));
107: }108: Console.WriteLine("Loaded " + a.Count + " data points.");
109: } 110: } 111: }Wednesday, 29 July 2009
R stuff for normal distribution fitting
Look at this site for more: http://www.bigre.ulb.ac.be/Users/jvanheld/statistics_bioinformatics/practicals/microarray_fitting_solutions.html
1: 2: # data loading3: filepath <- system.file("data", "morley.tab" , package="datasets")
4: mm <- read.table(filepath) 5: m <- mm[,1] 6: 7: hist(m) 8: 9: ## install 10: library(fBasics) 11: 12: skewness(m) 13: 14: kurtosis(m) 15: 16: plot(density(m)) 17: 18: plot(ecdf(m)) 19: 20: qqnorm(m) 21: abline(0,1) 22: 23: gal <- m 24: 25: ## Calculate estimators 26: m <- mean(gal,na.rm=T) 27: s <- sd(gal,na.rm=T) 28: 29: ## Draw the density histogram of the galactose microarray values30: h <- hist(gal,breaks=100,col='#CCCCFF',border='#CCCCFF',freq=F)
31: 32: ## On the histogram, draw vertical bars at the following values : 33: ## mean, mean + 1*sd, mean -1*sd, mean +2*sd, mean -2*sd34: abline(v=c(m,m-s,m-2*s,m+s,m+2*s),col="#000088",lwd=1)
35: 36: ## Superimpose the theoretical distribution37: lines(h$mids,dnorm(h$mids,m,s), type="l", lwd=2,col="red")
Thursday, 23 July 2009
SQL List indexes in db with fragmentation > 30 %
1: SELECT
2: OBJECT_NAME(object_id) ObjectName, 3: index_id, 4: index_type_desc, 5: avg_fragmentation_in_percent6: FROM sys.dm_db_index_physical_stats
7: (DB_ID('AdventureWorks'),NULL, NULL, NULL, 'LIMITED')
8: WHERE
9: avg_fragmentation_in_percent > 3010: ORDER BY
11: OBJECT_NAME(object_id)Tuesday, 21 July 2009
ADO and MARS
Very good article of using MARS for asynchronous data access. There are also other nice posts in the same website
http://www.emoreau.com/Entries/Articles/2006/11/MARS-and-Asynchronous-ADONet.aspx
http://www.emoreau.com/Entries/Articles/2006/11/MARS-and-Asynchronous-ADONet.aspx
Monday, 20 July 2009
WEKA machine learning applications
TClass -- A supervised learning algorithm for multivariate time series:
http://www.cse.unsw.edu.au/~waleed/tclass/
Weka - Modified for Data Mining Course at WPI http://davis.wpi.edu/~xmdv/weka/
http://www.cse.unsw.edu.au/~waleed/tclass/
Weka - Modified for Data Mining Course at WPI http://davis.wpi.edu/~xmdv/weka/
Friday, 17 July 2009
Wednesday, 15 July 2009
Friday, 10 July 2009
Mobile UK directory - remove
You might want to send this on to your friends in the UKMaybe you have heard about this but early next week all UK mobiles will be on a directory which will mean that anyone will be able to access the numbers. It is easy to unsubscribe but it must be done before the=0beginning of next week to make sure that you are ex directory. You could be swamped by unsolicited messages and calls. Removal is recommended by the BBC - see link below. http://news.bbc.co.uk/1/hi/programmes/working_lunch/8091621.stm
Just done this myself. Double checked it wasn't a scam and it is actually on the bbc website recommending doing this.The Directory of Mobile Phone numbers goes live next week. Apparently, all numbers including those belonging to children will be open to cold calling and the general abuse that less scrupulous telesales people subject us too.To remove your number go here. (you need your mobile phone with you to do this, they text youa code) http://www.118800.co.uk/removeme/remove-me.html
When on the site, click "Home" then "Ex-directory" this will remove you from the directory.You can remove your number from this list, and tell all your friends - especially those with children who have mobile phones. A mobile number is private and you should be able to choose who you give it to - none of us agreed to this when we signed our mobile phone contracts.
Just done this myself. Double checked it wasn't a scam and it is actually on the bbc website recommending doing this.The Directory of Mobile Phone numbers goes live next week. Apparently, all numbers including those belonging to children will be open to cold calling and the general abuse that less scrupulous telesales people subject us too.To remove your number go here. (you need your mobile phone with you to do this, they text youa code) http://www.118800.co.uk/removeme/remove-me.html
When on the site, click "Home" then "Ex-directory" this will remove you from the directory.You can remove your number from this list, and tell all your friends - especially those with children who have mobile phones. A mobile number is private and you should be able to choose who you give it to - none of us agreed to this when we signed our mobile phone contracts.
Thursday, 9 July 2009
Friday, 3 July 2009
SQL start end time timing
1: declare @starttime datetime
2: set @starttime = getdate()
3: 4: --SQL
5: 6: print ' ... substring took ' + cast(datediff(ms,@starttime,getdate()) as varchar) + 'ms'
7: set @starttime = getdate()
Thursday, 2 July 2009
Excel data reader library in codeplex
After doing quite a bit of research, this is the best and simplest excel data reader I managed to find for the .NET environment:
http://exceldatareader.codeplex.com/
http://exceldatareader.codeplex.com/
Wednesday, 1 July 2009
SQL output parameters in stored procedures
In C# add parameter of type output and obtain its value after cmd execution:
In sproc, declare the parameter as type output:
1: cmd.Parameters.Add("@newId", SqlDbType.Int);
2: cmd.Parameters["@newId"].Direction = ParameterDirection.Output;
3: cmd.ExecuteNonQuery();4: int result = (int)cmd.Parameters["@newId"].Value;
5: return result;
In sproc, declare the parameter as type output:
1: Create procedure... (
2: @param1 int, etc
3: @newId int OUTPUT
4: )5: begin
6: ...7: set @newId = 123
8: return
9: endThursday, 25 June 2009
Get database roles users principles
1: SET NOCOUNT ON
2: 3: --Execute two select statements.
4: SELECT 'IF NOT EXISTS (SELECT NULL FROM sys.sysusers WHERE [name] = ' +
5: QUOTENAME(dp2.[name],'''') + ') ' + CHAR(13) + ' CREATE USER ' +
6: QUOTENAME(dp2.name) + ' FOR LOGIN ' +
7: QUOTENAME(dp2.name)8: FROM sys.database_principals dp
9: JOIN sys.database_role_members rm ON dp.principal_id = rm.role_principal_id
10: JOIN sys.database_principals dp2 on dp2.principal_id = rm.member_principal_id
11: WHERE dp2.[name] != 'dbo'
12: AND dp.[name] = 'GroupNameHere'
13: 14: SELECT 'CREATE ROLE [GroupNameHere] AUTHORIZATION [dbo]'
15: UNION
16: --Returns database role members.
17: SELECT
18: 'EXEC sp_addrolemember N''' + dp.[name] + ''', N''' + dp2.[name] + ''''
19: FROM sys.database_principals dp
20: JOIN sys.database_role_members rm ON dp.principal_id = rm.role_principal_id
21: JOIN sys.database_principals dp2 on dp2.principal_id = rm.member_principal_id
22: JOIN sys.server_principals sp ON sp.sid = dp2.sid
23: WHERE dp2.[name] != 'dbo'
24: AND dp.[name] = 'GroupNameHere'
Wednesday, 24 June 2009
SQL return the insert row id
1: alter procedure [dbo].[usp_SomeName] (
2: @value varchar(100)
3: ) as
4: declare @id int
5: create table #out(id int, value varchar(100))
6: INSERT INTO test2
7: (value)
8: output inserted.* into #out
9: VALUES
10: (@value)
11: return (select top 1 id from #out)
SQL Error catching
1: begin catch
2: DECLARE
3: @ErrorMessage NVARCHAR(4000),4: @ErrorNumber INT,
5: @ErrorSeverity INT,
6: @ErrorState INT,
7: @ErrorLine INT,
8: @ErrorProcedure NVARCHAR(200);9: -- Assign variables to error-handling functions that capture information for RAISERROR.
10: SELECT
11: @ErrorNumber = ERROR_NUMBER(), 12: @ErrorSeverity = ERROR_SEVERITY(), 13: @ErrorState = ERROR_STATE(), 14: @ErrorLine = ERROR_LINE(),15: @ErrorProcedure = ISNULL(ERROR_PROCEDURE(), '-');
16: -- Build the message string that will contain original error information.
17: SELECT @ErrorMessage = 'Error %d, Level %d, State %d, Procedure %s, Line %d, ' + 'Message: '+ ERROR_MESSAGE();
18: -- Raise an error: msg_str parameter of RAISERROR will contain the original error information.
19: RAISERROR
20: ( 21: @ErrorMessage, 22: @ErrorSeverity, 23: 1,24: @ErrorNumber, -- parameter: original error number.
25: @ErrorSeverity, -- parameter: original error severity.
26: @ErrorState, -- parameter: original error state.
27: @ErrorProcedure, -- parameter: original error procedure name.
28: @ErrorLine -- parameter: original error line number.
29: );30: end catch
Tuesday, 23 June 2009
instant SQL print error message
set @msg = convert(varchar,getdate(),108) + ' - ' + some message here ...'
raiserror(@msg,0,1) with nowait
raiserror(@msg,0,1) with nowait
Thursday, 18 June 2009
Wednesday, 17 June 2009
SQL search for object by name, for one database only
1: SELECT name, type_desc, modify_date
2: FROM sys.objects
3: WHERE OBJECT_DEFINITION(object_id) LIKE '%somestring%'
Monday, 11 May 2009
Thursday, 23 April 2009
rounding errors between SQL and .NET - why helps to use decimal type instead of float
I came across a situation where when the database datatype is float, and we read the data into a .NET datatable, the automatic conversion is from float to double. For some reason when this happens there are occasionally cases of rounding errors. The way to overcome this (other than changing the float columns to decimal(18, 6) or some other decimal spec, is to access the float data using some CONVERT(decimal(18, 6) col_name_here) so that the .NET data table has decimal type in the column in question.
Wednesday, 22 April 2009
.NET Numeric Scientific Libraries
Overview article: http://www.infoq.com/news/2009/04/Meta-Numerics
Links to the 3 libraries mentioned in the article above:
Meta Numerics
IL Numerics
dnAnalytics
Links to the 3 libraries mentioned in the article above:
Meta Numerics
IL Numerics
dnAnalytics
Tuesday, 21 April 2009
cursor to fetch database views
1: declare @fetchStatus as int;
2: set @fetchStatus = 0
3: declare @str as varchar(100), @views as varchar(100)
4: declare tmp cursor for
5: select [name] from sys.views
6: open tmp
7: 8: while @fetchStatus = 0 begin
9: fetch tmp into @views
10: set @fetchStatus = @@fetch_status
11: if @fetchStatus = 0 begin
12: print @views
13: set @str = 'select * from ' + @views + ' where 0 = 1'
14: exec (@str)
15: end
16: end
17: 18: close tmp
19: deallocate tmp
Friday, 17 April 2009
Monday, 16 March 2009
Implement datetime (and other) sorting in ASP.NET gridview
We need some code to load data into the table, then we use the following functions (also add the gridView_Sorting function to handle the OnSorting event of the grid, in the gridview definition in the .aspx file (OnSorting="gridView_Sorting"), same for OnPageIndexChanging event: OnPageIndexChanging="gridView_PageIndexChanging").
1: static SortDirection lastSortDirection = SortDirection.Ascending;
2: static DataTable roadmapTable;
3: 4: static string ConvertSortDirectionToSql(SortDirection sortDirection)
5: {6: string m_SortDirection = String.Empty;
7: 8: switch (sortDirection)
9: {10: case SortDirection.Ascending:
11: m_SortDirection = "ASC";
12: break;
13: 14: case SortDirection.Descending:
15: m_SortDirection = "DESC";
16: break;
17: } 18: 19: return m_SortDirection;
20: } 21: 22: protected void gridView_PageIndexChanging(object sender, GridViewPageEventArgs e)
23: { 24: roadmapGridView.PageIndex = e.NewPageIndex; 25: roadmapGridView.DataBind(); 26: } 27: 28: protected void gridView_Sorting(object sender, GridViewSortEventArgs e)
29: {30: if (roadmapTable == null)
31: {32: return;
33: } 34: 35: lastSortDirection = lastSortDirection == SortDirection.Ascending ? SortDirection.Descending : SortDirection.Ascending; 36: 37: DataView m_DataView = new DataView(roadmapTable);
38: m_DataView.Sort = e.SortExpression + " " + ConvertSortDirectionToSql(lastSortDirection);
39: roadmapGridView.DataSource = m_DataView; 40: roadmapGridView.DataBind(); 41: }Wednesday, 4 March 2009
Speed up internet explorer
0. Start IE without addons
Go to Start > All Programs > Accessories > System Tools > Internet Explorer (No Add-ons)1. Disable the Phishing Filter
The Phishing Filter in IE7 is another area for performance improvement. If you mainly visit sites you trust and have used a lot, you can consider disabling the Phishing Filter in IE7.
- In the IE7 Tools menu, select Phishing Filter.
- In the submenu select Turn Off Automatic Website Checking.
2. Disable sounds in webpages, under options - advanced - multimedia
3. Disable RSS feed updates - under options - content - feeds
4. Increase max simultaneous connections - I am experimenting with 32 [Edit: max possible is 16 decimal...)
- Start the Registry Editor. From the Windows Start menu, select Run. In the Run box, type regedit and click OK.
- In the Registry Editor, locate the following key:
HKEY_CURRENT_USER\Software\Microsoft\Windows\ CurrentVersion\Internet Settings - With the key selected, open the Edit menu, click New and then select DWORD Value.
- In the name field for the new value, type MaxConnectionsPer1_0Server.
- Create another new DWORD Value and name it MaxConnectionsPerServer.
- Now right-click the new entries one-by-one, and select Modify in the popup menu.
- Enter the value for the maximum number of connections. By default Hexadecimal entry is selected, so if you type a value of 10 for these new DWORD values you will have a maximum of 16 downloads at the same time.
- Close the Registry Editor. Select Exit from the File menu.
- Finally reboot your computer and you’re ready to maximize your internet bandwidth usage by downloading multiple files at a time!
5. Limit reserved bandwidth to 0
- Open the Run option in the Start menu.
- Type gpedit.msc and click OK.
- Open the tree as shown in the image (Computer Configuration->Administrative Templates->Network->QoS Packet Scheduler).
- In the right-hand panel, double-click the Limit reservable bandwidth option.
- Next, change the option from Not Configured to Enabled.
the Bandwidth Limit (%) value, enter zero (0). - Click the OK button.
Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\Software\Microsoft\Internet Explorer\Toolbar\WebBrowser]
"ITBar7Position"=dword:00000001
undo the change:
Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\Software\Microsoft\Internet Explorer\Toolbar\WebBrowser]
"ITBar7Position"=-
7. Hide IE search box
Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\Software\Policies\Microsoft\Internet Explorer\InfoDelivery\Restrictions]
"NoSearchBox"=dword:00000001
and undo this
Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\Software\Policies\Microsoft\Internet Explorer\InfoDelivery\Restrictions]
"NoSearchBox"=dword:00000000
8. TCP IP Buffers
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters]"ForwardBufferMemory"=dword:00024a00
"NumForwardPackets"=dword:0000024a
"MaxForwardBufferMemory"=dword:00024a00
"MaxNumForwardPackets"=dword:0000024a
from http://www.msfn.org/board/lofiversion/index.php/t90257.html
Wednesday, 25 February 2009
PC Cooling Silent
Good site for advice on cooling your pc while keep noise levels to near silent J
http://www.silentpcreview.com/
http://www.silentpcreview.com/
Tuesday, 17 February 2009
SQL replace cursor with while loop
The key here is to get all the item categories which fit our WHERE clause into a memory table and use the Primary Key of this table to pick up each successive item category.
1: --Declare variables
2: DECLARE @item_category_id INT
3: DECLARE @order_id INT
4: DECLARE @purchase_order_id INT
5: 6: --Declare a memory table
7: DECLARE @item_table TABLE (primary_key INT IDENTITY(1,1) NOT NULL, --THE IDENTITY STATEMENT IS IMPORTANT!
8: item_category_id INT,
9: order_id INT
10: ) 11: 12: --now populate this table with the required item category values
13: INSERT INTO @item_table
14: SELECT -- Same SELECT statement as that for the CURSOR
15: it.item_category_id 16: ,ord.order_id17: FROM dbo.item_categories it
18: 19: INNER JOIN dbo.orders ord
20: ON ord.item_category_id = it.item_category_id
21: 22: WHERE ord.order_date >= '1-sep-05'
23: and it.isSuspended != 1
24: 25: DECLARE @item_category_counter INT
26: DECLARE @loop_counter INT
27: 28: SET @loop_counter = ISNULL(SELECT COUNT(*) FROM @item_table),0) -- Set the @loop_counter to the total number of rows in the
29: -- memory table
30: 31: SET @item_category_counter = 1
32: 33: WHILE @loop_counter > 0 AND @item_category_counter <= @loop_counter
34: BEGIN
35: SELECT @item_category_id = item_category_id
36: ,@order_id = order_id37: FROM @item_table
38: WHERE primary_key = @item_category_counter
39: 40: --Now pass the item-category_id and order_id to the OUTPUT stored procedure
41: EXEC dbo.usp_generate_purchase_order @item_category_id, @order_id, @purchase_order_id OUTPUT
42: 43: /*44: Call other code here to process your pruchase order for this item
45: */ 46: 47: SET @item_category_counter = @item_category_counter + 1
48: ENDFriday, 13 February 2009
SQL Statistics information
from an amazing blog post here http://www.mssqltips.com/tip.asp?tip=1550 : (recommended to read)
ALTER PROCEDURE [dbo].[usp_Detail_Index_Stats] @table_name sysname
AS
----------------------------------------------------------------------------------
-- ******VARIABLE DECLARATIONS******
----------------------------------------------------------------------------------
DECLARE @IndexTable TABLE
(
[Database] sysname, [Table] sysname, [Index Name] sysname NULL, index_id smallint,
[object_id] INT, [Index Type] VARCHAR(20), [Alloc Unit Type] VARCHAR(20),
[Avg Frag %] decimal(5,2), [Row Ct] bigint, [Stats Update Dt] datetime
)
DECLARE @dbid smallint --Database id for current database
DECLARE @objectid INT --Object id for table being analyzed
DECLARE @indexid INT --Index id for the target index for the STATS_DATE() function
----------------------------------------------------------------------------------
-- ******VARIABLE ASSIGNMENTS******
----------------------------------------------------------------------------------
SELECT @dbid = DB_ID(DB_NAME())
SELECT @objectid = OBJECT_ID(@table_name)
----------------------------------------------------------------------------------
-- ******Load @IndexTable with Index Metadata******
----------------------------------------------------------------------------------
INSERT INTO @IndexTable
(
[Database], [Table], [Index Name], index_id, [object_id],
[Index Type], [Alloc Unit Type], [Avg Frag %], [Row Ct]
)
SELECT
DB_NAME() AS "Database"
@table_name AS "Table"
SI.NAME AS "Index Name"
IPS.index_id, IPS.OBJECT_ID, --These fields included for joins only
IPS.index_type_desc, --Heap, Non-clustered, or Clustered
IPS.alloc_unit_type_desc, --In-row data or BLOB data
CAST(IPS.avg_fragmentation_in_percent AS decimal(5,2)),
IPS.record_count
FROM sys.dm_db_index_physical_stats (@dbid, @objectid, NULL, NULL, 'sampled') IPS
LEFT JOIN sys.sysindexes SI ON IPS.OBJECT_ID = SI.id AND IPS.index_id = SI.indid
WHERE IPS.index_id <> 0
----------------------------------------------------------------------------------
-- ******ADD STATISTICS INFORMATION******
----------------------------------------------------------------------------------
DECLARE curIndex_ID CURSOR FOR
SELECT I.index_id
FROM @IndexTable I
ORDER BY I.index_id
OPEN curIndex_ID
FETCH NEXT FROM curIndex_ID INTO @indexid
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @IndexTable
SET [Stats Update Dt] = STATS_DATE(@objectid, @indexid)
WHERE [object_id] = @objectid AND [index_id] = @indexid
FETCH NEXT FROM curIndex_ID INTO @indexid
END
CLOSE curIndex_ID
DEALLOCATE curIndex_ID
----------------------------------------------------------------------------------
-- ******RETURN RESULTS******
----------------------------------------------------------------------------------
SELECT I.[Database], I.[Table], I.[Index Name], "Index Type"=
CASE I.[Index Type]
WHEN 'NONCLUSTERED INDEX' THEN 'NCLUST'
WHEN 'CLUSTERED INDEX' THEN 'CLUST'
ELSE 'HEAP'
END,
I.[Avg Frag %], I.[Row Ct],
CONVERT(VARCHAR, I.[Stats Update Dt], 110) AS "Stats Dt"
FROM @IndexTable I
ORDER BY I.[Index Type], I.[index_id]
More on SQL indexes
the command to show index statistics:
dbcc show_statistics (tablename, indexname)
The lower the "All density" value the better, means the index is highly selective.
--
How to view index fragmentation (replace database and table names)
How to reorganise an index (online operation) - only affects the leaf nodes.
To rebuild the index without taking the database offline you need the enterprise edition of MSSQL 2005.
If space is an issue it is better to disable a nonclustered index before rebuilding it, then we only need about 20% of the index size as free space to do the rebuild.
Also the Fill Factor can be adjusted based on how we expect the data to be used. This specifies how full the data pages or leaf level index pages will be. Lower fill factor is better when there are many data updates and inserts.
dbcc show_statistics (tablename, indexname)
The lower the "All density" value the better, means the index is highly selective.
--
How to view index fragmentation (replace database and table names)
1: select str(s.index_id,3,0) as indid,
2: left(i.name, 20) as index_name,
3: left(index_type_desc, 20) as index_type_desc,
4: index_depth as idx_depth,
5: index_level as level,
6: str(avg_fragmentation_in_percent, 5,2) as avg_frgmnt_pct,
7: str(page_count, 10,0) as pg_cnt
8: FROM sys.dm_db_index_physical_stats
9: (db_id('_DBNAME_<dbname>'), object_id('<tablename>_TABLENAME_'),1, 0, 'DETAILED') s
10: join sys.indexes i on s.object_id = i.object_id and s.index_id = i.index_id
How to reorganise an index (online operation) - only affects the leaf nodes.
1: 2: ALTER INDEX <indexname> _INDEXNAME_ on _TABLENAME_ <tablename> REORGANIZE
1: ALTER INDEX _INDEXNAME_ on _TABLENAME_ REBUILD
If space is an issue it is better to disable a nonclustered index before rebuilding it, then we only need about 20% of the index size as free space to do the rebuild.
Also the Fill Factor can be adjusted based on how we expect the data to be used. This specifies how full the data pages or leaf level index pages will be. Lower fill factor is better when there are many data updates and inserts.
Thursday, 12 February 2009
Clustered and non-clustered indexes in MSSQL server
Columns to include in clustered index
. Those that are often accessed sequentially
. Those that contain a large number of distinct values
. Those that are used in range queries that use operators such as BETWEEN, >
<= in the WHERE clause . Those that are frequently used by queries to join or group the result set When to use non-clustered index . Queries that do not return large result sets . Columns that are frequently used in the WHERE clause that return exact match . Columns that have many distinct values (that is, high cardinality) . All columns referenced in a critical query (A special nonclustered index called a covering index that eliminates the need to go to the underlying data pages.) (based on the book SQL Server 2005 Unleashed, Sams 2006). Note: if there are columns usually required in the results but not in the query conditions, we can add them as "included columns" (for non-clustered index), which means they will exist in the leaf nodes of the index for faster retrieval. This is similar to a covering index (same?) To improve index performance, we can "REBUILD" them (drop and recreate) or just "REORGANIZE" them (like defrag, without drop). When we reorganise we have the option to compact large objects. Index can be disabled, in this case if we rebuild it we don't need to have extra temp space. Index can be applied on a view, but there are several conditions that must be met before this can be done. See online documentation. A composite index will only be used optimally (i.e. index seek instead of index scan) if its first column is part of the search argument or join clause. When deciding on an index another parameter to consider is the selectivity of the index i.e. the number of distinct rows returned on the index keys / number of rows in the table. The higher this number the better. e.g.
as a rule of thumb we require this to be > 0.85
Example sql code to determine the statistical distribution of values for a specific column
. Those that are often accessed sequentially
. Those that contain a large number of distinct values
. Those that are used in range queries that use operators such as BETWEEN, >
<= in the WHERE clause . Those that are frequently used by queries to join or group the result set When to use non-clustered index . Queries that do not return large result sets . Columns that are frequently used in the WHERE clause that return exact match . Columns that have many distinct values (that is, high cardinality) . All columns referenced in a critical query (A special nonclustered index called a covering index that eliminates the need to go to the underlying data pages.) (based on the book SQL Server 2005 Unleashed, Sams 2006). Note: if there are columns usually required in the results but not in the query conditions, we can add them as "included columns" (for non-clustered index), which means they will exist in the leaf nodes of the index for faster retrieval. This is similar to a covering index (same?) To improve index performance, we can "REBUILD" them (drop and recreate) or just "REORGANIZE" them (like defrag, without drop). When we reorganise we have the option to compact large objects. Index can be disabled, in this case if we rebuild it we don't need to have extra temp space. Index can be applied on a view, but there are several conditions that must be met before this can be done. See online documentation. A composite index will only be used optimally (i.e. index seek instead of index scan) if its first column is part of the search argument or join clause. When deciding on an index another parameter to consider is the selectivity of the index i.e. the number of distinct rows returned on the index keys / number of rows in the table. The higher this number the better. e.g.
1: select count(distinct surname) from sometable / select count(*) from sometable
as a rule of thumb we require this to be > 0.85
Example sql code to determine the statistical distribution of values for a specific column
1: select state, count(*) as numrows, count(*)/b.totalrows * 100 as percentage
2: from authors a, (select convert(numeric(6,2), count(*)) as totalrows from authors) as b group by state, b.totalrows
3: having count(*) > 1
4: order by 2 desc
5: goFriday, 6 February 2009
SQL datetime as string representation
1: CONVERT(VARCHAR(10), [StartDate], 103)
Also experiment with different values instead of 10, to get only the days/month part of date for example.
Thursday, 5 February 2009
GreyBox popup window with C# ASP.NET DataBound GridView application
GreyBox is a nice free animated popup window: http://orangoo.com/labs/GreyBox/
In order to get it to work dynamically with a databound GridView in ASP.NET in C# I had to make the following change in the .aspx page:
in the part of the gridview definition, added another template field:
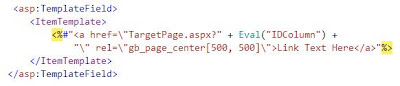
and of course include the greybox folder in the website, and the correct entries in the header section. I hope this helps someone, it took me some time to figure out.
In order to get it to work dynamically with a databound GridView in ASP.NET in C# I had to make the following change in the .aspx page:
in the

Friday, 30 January 2009
get database views based on system table - uses cursor
1: declare @fetchStatus as int; set @fetchStatus = 0
2: declare @str as varchar(100), @views as varchar(100)
3: declare tmp cursor for
4: 5: select [name] from sys.views
6: 7: open tmp
8: 9: while @fetchStatus = 0 begin
10: fetch tmp into @views
11: set @fetchStatus = @@fetch_status
12: if @fetchStatus = 0 begin
13: print @views
14: set @str = 'select * from ' + @views + ' where 0 = 1'
15: exec (@str)
16: end
17: end
18: 19: close tmp
20: deallocate tmp
Monday, 12 January 2009
MSSQL catch block to raiseerror using ErrorMessage, ErrorSeverity and ErrorState
1: BEGIN CATCH
2: 3: DECLARE @ErrorMessage NVARCHAR(4000)
4: DECLARE @ErrorSeverity INT
5: DECLARE @ErrorState INT
6: 7: SELECT
8: @ErrorMessage = ERROR_MESSAGE(), 9: @ErrorSeverity = ERROR_SEVERITY(), 10: @ErrorState = ERROR_STATE(); 11: 12: RAISERROR (@ErrorMessage, -- Message text.
13: @ErrorSeverity, -- Severity.
14: @ErrorState -- State.
15: ); 16: 17: END CATCH
Subscribe to:
Comments (Atom)